The loan market in Australia, like many markets, is heavily concentrated around a handful of large lenders (CBA,ANZ,NAB,WBC) and brokerages (Aussie Home Loans, Mortgage Choice) who dominate.
These providers have large balance sheets and advertising budgets to capture funnel and convert customers based on price and increasingly advanced analytics.
They also tend to fish in the centre of the market. To compete lenders must know their market at a very fine grained level. Knowing who their customers are and on what differentiated basis to lend to them. Whilst many have used the same marketing campaigns and lending decisioning ratios and measures in the past, tuning these presents competitive advantage.
Lenders collect loan applications manually but increasingly electronically. Moroku Lending is one example digital form of loan origination, allowing borrowers to apply online and lenders to process those loan applications. These systems typically have two parts:
During the application process, borrowers submit
Personal Details – Age, Location, Gender, Martial and Employment Status, Credit Score
Financial Details – Assets and Liabilities, Expenses and Income
Loan Details – How much they want to borrow for what
The lender then reviews this data, through a combination of manual checks and calculations to determine whether to lend the customer the money and on what terms.
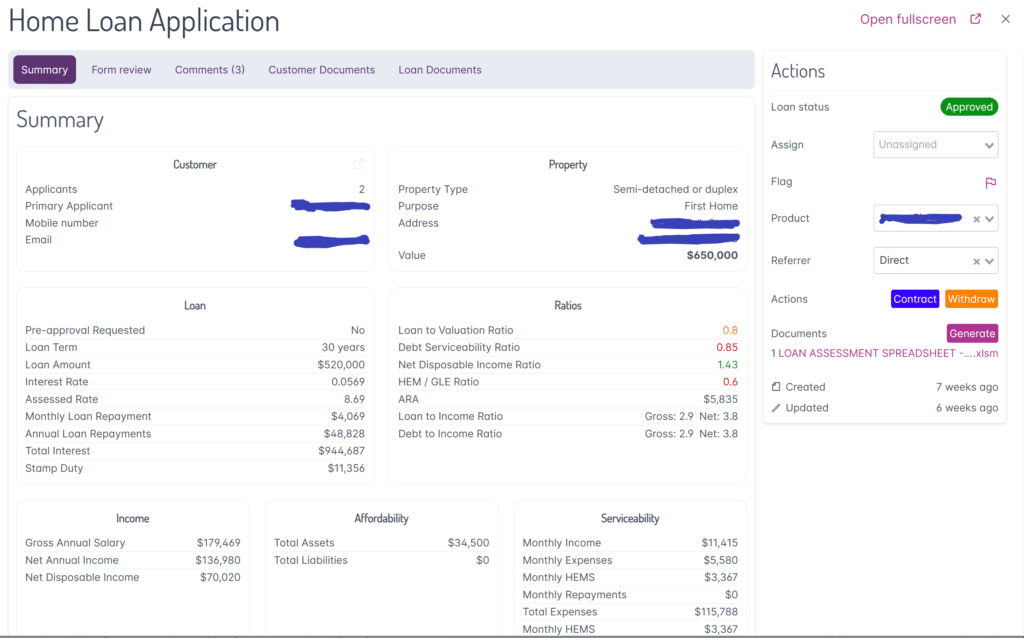
Ratios are commonly used to guide the decision
Loan to Valuation Ratio
Debt Serviceability Ratio
Net Disposable Income Ratio
HEM / GLE Ratio
ARA
Loan to Income Ratio – Gross and net
Debt to Income Ratio, Gross & Net
Moroku hypothesises that many lenders do not know the statistical correlation of the inputs to the outputs. That is to say that they do not understand mathematically the relationship between the data they are asking for and the decisions they are making. This makes risk management difficult and processing slow and ambiguous. By understanding the relationships and being forced to mathematically define risk, risk management will be improved and decisioning made faster.
Regression Research Methodology
Following the establishment of the hypothesis, the researchers reviewed multiple statistical correlation models for utility – non linear regression, liner regression, neural networks , other non AI . This phase included familiarisation by the team of the loan origination process – what data is collected and how is it used.
From there a data lab was set up to capture data, clean and preprocess it, normalising numerical variables, and encoding categorical variables to ensure consistency and accuracy across a standardised data model.
An analytics and model platform was also established using Python as the base programming language and a set of open-source machine learning libraries. This tooling provided a wide range of tools for supervised and unsupervised learning, including classification, regression, clustering, and dimensionality reduction. It included various algorithms like support-vector machines, random forests, gradient boosting, k-means, and DBSCAN.
Once the data environment was established an initial feature set was identified to identify the most relevant features (predictors) that influence loan approval decisions. This was done using techniques like correlation analysis and feature importance ranking.
Using the regression algorithms (e.g., linear regression, logistic regression), models were built on an initial data set to establish initial patterns and relationships between the features and the approval outcomes.
The model’s performance was then evaluated using metrics such as accuracy, precision, recall, and F1 score to understand how well the model predicts loan approvals and gather insights into which factors are most influential in the decision-making process.
Initial Results

The model correctly classified about 55.56% of the samples, but imbalanced datasets, with a bias around approved loans makes this metric unreliable.
While the model’s accuracy is relatively low at 55.56%, the high ROC-AUC score of 0.8824 suggests that is good at ranking predictions correctly, indicating potential.
The extreme class imbalance, with 90% of loan approavals, significantly affects the model’s performance, with the precision and recall metrics indicating that improvements are needed, especially for predicting rejections.
The next step is to broaden the data set not only in terms of size but also in terms of balance of rejections and approvals.